


El famoso László Babai (Premio Knuth 2015) afirma haber demostrado que la complejidad algorítmica del problema del isomorfismo de grafos es cuasipolinómica. Catedrático de la Universidad de Chicago, EEUU, ha impartido una charla en su propia universidad para explicar su demostración, basada en combinar la teoría de grupos y la combinatoria. El vídeo de la charla permite hacerse una idea de la prueba. Sin embargo, para saber si la demostración es correcta habrá que esperar a la publicación del artículo y su revisión detallada por parte de los expertos.
Imitando a la NASA, que anuncia sus logros en rueda de prensa antes de que el artículo científico se publique, Laci, a sus 65 años, no ha hecho pública su demostración (aún). Quizás ha enviado el artículo a revisión por pares (en cuyo caso habrá que esperar más de un año para que se haga público). Este tipo de resultados tan importantes en teoría de la complejidad los suelen demostrar investigadores jóvenes (en el mejor momento de su vida). Babai podría ser la excepción que confirma la regla (cual Karl Weierstrass).
Espero que no le pase a Babai lo que le pasó a Andrew Wiles (su primera versión de la demostración del último teorema de Fermat contenía un error y tuvo que recurrir a su ex-alumno Richard Taylor para corregirlo). En su caso, Babai podría recurrir a su ex-alumno Paolo Codenotti. No pienses mal, pero siempre hay que desconfiar de quien anuncia a bombo y platillo una demostración matemática aún sin publicar. Como no hay artículo que citar, solo puedo recomendar algunos blogs.
Te recomiendo leer a Jeremy Kun, «A Quasipolynomial Time Algorithm for Graph Isomorphism: The Details,» Math ∩ Programming, 12 Nov 2015; Dick Lipton, Ken Regan, «A Little More on the Graph Isomorphism Algorithm,» Gödel’s Lost Letter and P=NP, 21 Nov 2015.
Por supuesto, si quieres algo más divulgativo, mejor Adrian Cho, «Mathematician claims breakthrough in complexity theory,» News, Science, 10 Nov 2015; Lance Fortnow, «A Primer on Graph Isomorphismm,» Computational Complexity, 12 Nov 2015; Tom Simonite, «Claimed Breakthrough Slays Classic Computing Problem; Encryption Could Be Next,» MIT Technology Review, 13 Nov 2015; y Scott Aaronson, «G. Phi. Fo. Fum.,» Shtetl-Optimized, 12 Nov 2015.
El vídeo de la charla nos muestra a Laci Babai delante de una pizarra, tiza en mano, exponiendo las ideas básicas de la demostración. Gracias a este vídeo varios blogueros han publicado las líneas maestras de la demostración. Por supuesto, que la idea de una demostración indique que el camino seguido es prometedor no es indicativo de que la demostración sea correcta. El diablo está en los detalles y Babai podría haber cometido un error sutil que solo la atenta mirada de los expertos pueden desvelar. Cuando se publique el artículo volveré a hablar sobre este asunto. Mientras tanto te ofrezco una breve revisión sobre el problema del isomorfismo de grafos y su importancia en el campo de la complejidad computacional.

El problema del isomorfismo de grafos es sencillo de formular: determinar si dos grafos con el mismo número de nodos son idénticos si se identifican de forma adecuada sus nodos. Esta figura muestra un ejemplo sencillo, dos grafos con n=8 nodos llamados {a, b, c, d, g, h, i, j} en el de la izquierda y {1, 2, 3, 4, 5, 6, 7, 8} en el de la derecha. Una identificación adecuada permite mostrar que se trata del mismo grafo, pero dibujado de forma diferente.
Para resolver este problema a la fuerza bruta hay que considerar todas las n! identificaciones posibles entre los n nodos del grafo (8! = 40320). Como el factorial crece de forma exponencial (n! ~ nn), no se trata de un algoritmo en P (problemas cuya solución se determina de forma eficiente en tiempo polinómico); sin embargo, como verificar si una solución es correcta está en P, entonces se trata de un problema en NP. Por supuesto, podría ocurrir que el problema del isomorfismo de grafos estuviera en la clase P, o incluso en la clase NP-completo, pero aún no lo sabemos. Los interesados en más detalles pueden consultar el libro de J. Kobler, U. Schöning, J. Toran, «The Graph Isomorphism Problem. Its Structural Complexity,» Birkhäuser (1993).
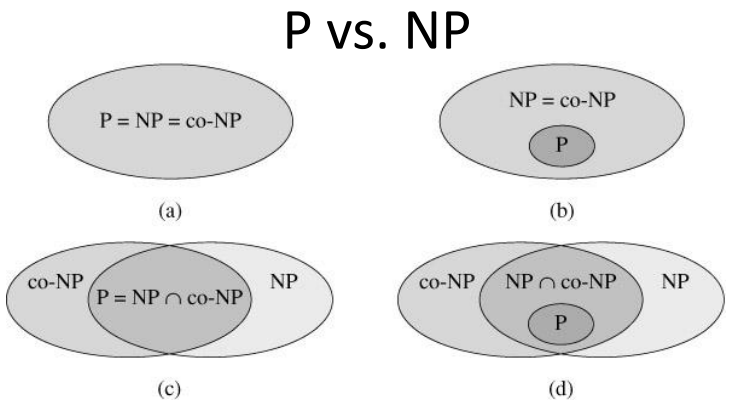
Se ha conjeturado que el problema del isomorfismo de grafos está en P, pero no está en NP-completo La razón es que en la práctica se trata de un algoritmo en P, ya que hay muchos algoritmos que usan heurísticos (como Nauty, bliss, o Saucy3) que resuelven este problema de forma muy eficiente en la mayoría de los casos (aunque el peor caso posible siempre se escape de P y se encuentre en NP). Se sabe que este problema está en NP y en co-NP (lo que es un indicio firme de que no está en NP-completo). Muchos problemas están en NP ∩ co-NP, como la factorización de números primos, o los tests de primalidad (de hecho, como me recuerda Alberto Márquez, aka @twalmar, determinar si un número es primo está en P, lo que es más preciso). La relación entre las clases de complejidad P, NP y co-NP forma parte del problema P vs NP.
¿Para qué sirve el problema? Como suele ser habitual, este tipo de problemas tiene muy pocas aplicaciones prácticas (y en su caso se usan variantes específicas adaptadas a cada aplicación). En teoría se usa en química computacional para buscar en bases de datos de compuestos químicos (el grafo conecta los átomos de la molécula). También se ha propuesto en sistemas OCR de reconocimiento de caracteres manuscritos, para analizar redes en ciencias sociales, comparar grafos en sistemas de información geográfica y otras aplicaciones de comparación de ficheros de datos. Pero en todas estas aplicaciones se usan algoritmos específicos, inspirados en el problema del isomorfismos de grafos, pero usando heurísticos específicos para cada aplicación; no creo que nadie use este algoritmo tal cual.
¿Qué sabemos sobre la complejidad computacional del problema? En 1983, Eugene M. Luks, de la Universidad de Oregon, y Babai demostraron que la complejidad del algoritmo es O(exp((n log n)1/2)), próxima a ser cuasipolinómica (la exponencial de una potencia del logaritmo). Si la demostración de Babai es correcta, la complejidad sería O(exp((log n)c)) para alguna constante c, es decir, sería cuasipolinómica. En dicho caso, se habrá dado un paso de gigante hacia la futura demostración de que no está en la clase NP-completo. Más aún, si el problema no estuviera en P, ni tampoco en NP-completo, entonces sería un problema NP-intermedio; recuerda que NPI=NP−(P ∪ NP-c). Sería el primer problema conocido en esta clase de complejidad. Por tanto, el resultado de Babai es un paso de gigante hacia uno de los grandes resultados en teoría de la complejidad del siglo XXI.
Me he leído varios blogs que explican la idea de la demostración de Babai, pero hasta que no se publique el artículo prefiero no comentar más detalles aquí. Lo importante del trabajo de Babai es que podría ser un motor para que muchos investigadores jóvenes intenten demostrar que el problema de isomorfismo de grafos está en P. Muchos resultados muy interesantes pueden surgir de dicho trabajo.
Si NP-Intermedio no es vacío entonces ¿podriamos decir que NP≠P?
Pedro, no, no es tan sencillo. Sabemos que NP-c no es vacío, ¿significa que NP≠P? No, porque podría ser que NP=P=NP-c. Lo mismo pasa si NPI no es vacío, puede ser que o bien NP≠P y P≠NPI, o bien NP=P y P=NPI; lo que nos indica NPI no vacío es que NP≠NP-c si se tiene que NP≠P (como todo el mundo piensa). Imagina un diagrama de conjuntos y verás mejor lo que digo.
Gracias. Cierto.
Pues hombre como «c» sea un poco grandecito no estoy seguro de que se pueda considerar cuasipolinómico. Por ejemplo si c=e , el coste para 43 variables sería de entorno a 40 ceros detrás de un 1, mientras que por fuerza bruta, sin optimizar nada, sería de orden factorial, unos 50 y pico. Con un algoritmo de reducción bien afinado, usando estructuras de datos adecuadas, se puede sacar en orden 2^n-1, lo cual serían apenas 12 ceros para 43 variables; incluso para 200 variables saldrían 59 ceros frente a los 90 y pico de Babai. Para más variables ya la calcu se me vuelva loca.
El trabajo ya lo ha publicado en arxiv (https://arxiv.org/abs/1512.03547), y efectivamente, ha necesitado un par de correcciones; lo cual no me extraña en 89 páginas de lemas, corolarios y observaciones entrelazadas. En cualquier caso mientras el planteamiento (razonamiento de base) sea bueno, si la idea hace ese clic mágico en la cabeza, lo demás son formalismos.