


Me han preguntado varias veces por los detalles de hardware y software de la versión de AlphaGo (Google DeepMind) que ha vencido al Go a Lee Sedol en marzo de 2016. Se ha usado la misma máquina que venció a Fan Hui en octubre de 2015. Una versión distribuida de AlphaGo que usa 1202 CPU, 176 GPU, y 40 hebras (threads) de búsqueda. Se estimó en enero de 2015 que su Elo es de 3140 (una versión con 1920 CPU, 280 GPU y 64 hebras alcanza un Elo estimado de 3168). Dicho valor debe ser comparado con los Elo de Fan Hui (~2750) y de Lee Sedol (~2940); por cierto, recuerda que el Elo máximo posible para un humano es 3000.
El algoritmo de AlphaGo usa dos redes de neuronas artificiales de tipo convolucional, una de evaluación (value network), que estima la probabilidad de que la posición actual permita ganar, y otra de estrategia (policy network), que evalúa todos y cada uno de los movimientos permitidos en la posición actual. Son redes tipo perceptrón multicapa (feedforward networks) que imitan la corteza visual primaria (V1) de un mamífero. Este tipo de redes convolucionales se usan mucho en la clasificación de imágenes. Ambas redes de AlphaGo tienen 13 capas ocultas, cada una con unas 260 mil neuronas y unos 2,7 millones de pesos. Entre cada par de capas se aplican filtros que suavizan la imagen, cuyo objetivo a agregar la información de la imagen y generalizar los patrones observados. AlphaGo aplica un total de 192 filtros (aunque se han probado versiones con hasta 384 filtros).
Toda la información técnica disponible aparece en el apéndice de métodos (Methods) del artículo de David Silver et al., «Mastering the game of Go with deep neural networks and tree search,» Nature 529: 484–489 (28 Jan 2016), doi: 10.1038/nature16961 [PDF]; recomiendo también Christopher Clark, Amos Storkey, «Teaching Deep Convolutional Neural Networks to Play Go,» arXiv:1412.3409 [cs.AI], Christopher Clark, Amos Storkey, «Training Deep Convolutional Neural Networks to Play Go,» Proc. 32nd Int. Conf. on Machine Learning, Lille, France, 2015 [PDF].

Esta figura muestra el efecto en el Elo estimado del número de hebras de búsqueda y el número de GPU. En la implementación asíncrona (no distribuida) se usa un ordenador (single machine) con 48 CPU y hasta 8 GPU. En la implementación distribuida se usan múltiples ordenadores conectados en red (grid computing) con hasta 1920 CPU y hasta 280 GPU. El factor más importante es el número de hebras de búsqueda que se usan en el algoritmo de búsqueda en árbol de tipo Montecarlo.

Las redes de neuronas artificiales convolucionales fueron introducidas en 1980 para resolver problemas de clasificación de imágenes. Se basan en los trabajos de Hubel y Wiesel en 1959 sobre el funcionamiento de la corteza visual primaria V1. Dichas neuronas se agrupan en capas y se activan en función de patrones visuales localizados (como la presencia de bordes y su orientación relativa). En inteligencia artificial se imita el funcionamiento de estas neuronas mediante la aplicación de filtros a pequeñas regiones de la imagen (máscaras). A partir de la imagen original se extraen varias imágenes de características (que dependen del problema concreto a resolver). Se aplican filtros a estas imágenes de características que simplifican (agregan) los patrones de la imagen y los transfieren de capa en capa de neuronas.
Imagina, por ejemplo, que quieres reconocer imágenes que muestren perros. Durante el entrenamiento, se muestra a la red neuronal muchas imágenes tanto con perros como sin perros. Se le dice a la red qué imágenes muestran perros y cuáles no. El algoritmo de aprendizaje (supervisado) ajusta los pesos sinápticos que conectan las neuronas artificiales para maximizar la probabilidad de acierto de la red en la clasificación. Tras el entrenamiento, la red es capaz de generalizar la información aprendida, es decir, cuando se la muestra una imagen diferente de las usadas en el entrenamiento, la red responde si corresponde a un perro o no. No hay que explicarle a la red que los perros son animales, con cabeza, cuerpo, patas, etc. La red aprende sola qué características diferencian las imágenes con perros que se le mostraron en el entrenamiento de las que no los contienen.
Parece sorprendente que la red sea capaz de generalizar la información aprendida y clasificar de forma correcta imágenes que no le fueron presentadas durante el entrenamiento. Aún no sabemos exactamente cómo ocurre este proceso. Todo apunta a que la red almacena un potencial energético con los patrones a reconocer almacenados en mínimos locales. Algo así como un paisaje con montañas y valles, donde los patrones se almacenan en los valles y las montañas separan unos valles de otros. Cuando se le muestra una imagen es como si se soltara una gran pelota en algún lugar del paisaje y la pelota rodara cuesta abajo hasta alcanzar un valle (el patrón más parecido al observado).
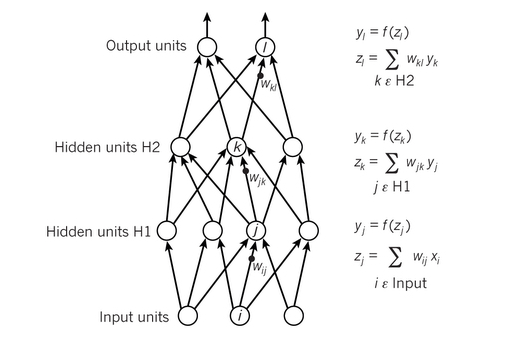
Las conexiones entre las neuronas de las diferentes capas (que se llaman ocultas para diferenciarlas de las capas de entrada y salida) se describen mediante pesos sinápticos. Los algoritmos de aprendizaje son capaces de ajustar los valores de estos pesos durante la fase de entrenamiento (aprendizaje) para minimizar los errores máximos en la clasificación de la red.
Por supuesto, diseñar y entrenar una red convolucional parece fácil, pero no lo es (como sabe cualquiera que lo haya intentado). En la práctica aparecen muchas complicaciones técnicas, como la elección del número adecuado de capas de neuronas, el número de neuronas por capa, el tamaño de los filtros, etc., que influyen mucho en la capacidad de generalización de la red. Aún así, este tipo de neuronas (sobre todo con un número pequeño de capas de neuronas) se han usado mucho en las últimas décadas. Hoy en día se están empezando a usar muchas capas (más de 10), muchas neuronas (cientos de miles) y muchos pesos sinápticos (decenas de millones). En los próximos lustros asistiremos a la aparición de redes con millones de neuronas o, incluso, con miles de millones de neuronas. Que nadie sienta temor, todavía hace falta mucha investigación sobre cómo diseñar dichas redes y cómo entrenarlas de forma adecuada.
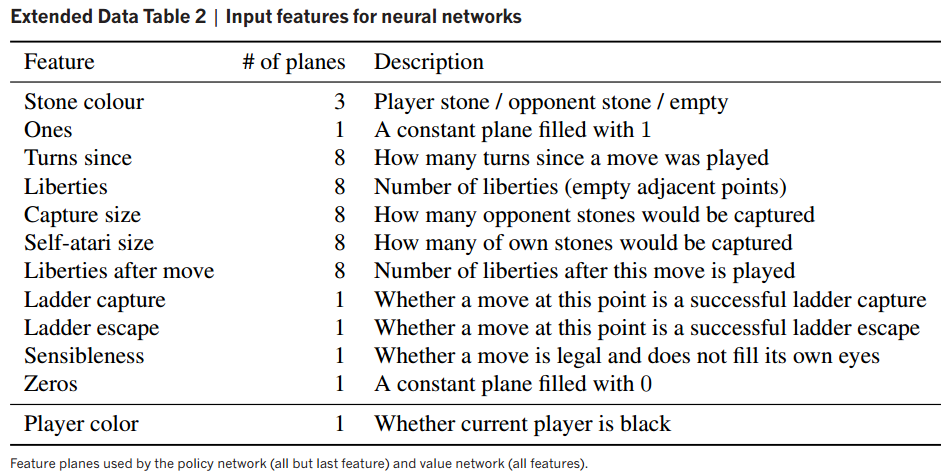
Volvamos a las dos redes de neuronas convolucionales de AlphaGo. La entrada son 48 imágenes del tablero 19 × 19 que muestran las 48 características diferentes indicadas en esta tabla. Por ejemplo, «Stone colour» son tres imágenes del tablero solo con las piedras del jugador, solo con las del oponente y solo con los cuadrados vacíos. La primera capa trasforma la entrada en una imagen de 23 × 23 (se rellenan a blanco los datos faltantes), luego la primera capa tiene 23 × 23 × 48 neuronas; dicha imagen se filtra con un máscara de 5 × 5 para pasarla a la siguiente capa, luego el número de pesos sinápticos es de 23 × 23 × 48 × 25. Las capas de la 2 a la 12 usan imágenes de 21 × 21 a la que aplican filtros con máscaras de 3 × 3, luego tienen 21 × 21 × 48 neuronas por capa y 21 × 21 × 48 × 9 pesos sinápticos.
Para la red de evaluación (value network) la última capa devuelve un número, una estimación de la probabilidad de ganar con el tablero de entrada. Cuando dicho valor es menor del 20%, AlphaGo se rinde (como ocurrió en la cuarta partida contra Lee Sedol). La red de estrategia (policy network) evalúa todos los movimientos legales de la posición actual (como máximo 361, en promedio unos 250) y estima la probabiliidad de que se trate del mejor movimiento posible. Esta información se usa para sesgar el árbol de búsqueda del algoritmo de Montecarlo.
En los programas de ajedrez, damas y similares se usa una función de evaluación de la posición que se basa en heurísticos que recopilan el conocimiento experto de los grandes maestros (dominio del centro, número de piezas desprotegidas, número de piezas del oponente atacadas, etc.). En AlphaGo se prescinde de dicho conocimiento experto (porque los grandes jugadores de Go no saben realmente por qué juegan como lo hacen y hablan de cosas como intuición y creatividad difíciles de incorporar en un programa de ordenador).
Las redes de neuronas de evaluación y estrategia fueron entrenadas usando aprendizaje supervisado con 30 millones de movimientos de partidas de jugadores profesionales (KGS Go Server). La red neuronal era capaz de predecir el 57% de los movimientos realizados por humanos. Luego AlphaGo fue entrenada mediante aprendizaje con refuerzo contra los mejores programas de Go del mercado (Pachi, Fuego, etc.). Pero la fase más importante fue el juego de AlphaGo contra sí misma (en realidad contra una versión anterior de AlphaGo seleccionada de forma aleataria entre las últimas cien versiones). Esta última fase ha sido la clave de la victoria contra Lee Sedol. Desde que Alpha Go le ganó a Fan Hui ha jugado millones de partidas contra sí misma, reforzando su nivel de juego hasta niveles inauditos.

La red neuronal de estrategia puntúa todas las casillas libres con una valoración de la probabilidad de ganar si se coloca en cada una de dichas casillas una piedra. El algoritmo de Montecarlo selecciona las posiciones con mayor valoración y ejecuta una búsqueda sistemática que refina dicha estimación. Al final se combina (agrega) la información heurística de la red con la fuerza bruta (sesgada) del Montecarlo y se selecciona el mejor movimiento. No quiero entrar detalles técnicos sobre cómo se usa estadística bayesiana para combinar dichas probabilidades. Los interesados pueden consultar el artículo.
En resumen, espero haber satisfecho la curiosidad de quienes me preguntan sobre AlphaGo. Hay muchas más cosas que no he contado (como el funcionamiento del algoritmo de Montecarlo con poda alfa-beta). Aunque Google DeepMind lleve menos de dos años trabajando en este proyecto, no debemos olvidar que AlphaGo es el resultado de medio siglo de investigación en inteligencia artificial.
Gracias Francis, una duda.
Si la red neuronal está hecha con software (supongo) ¿Como es posible que no se entienda como puede generalizar conceptos?
Perico, en redes con pocas neuronas más o menos se entiende cómo generaliza la red (cómo se amplía la cuenca de atracción de los mínimos que almacenan patrones conforme la red aprende), pero con redes con mayor número de neuronas todavía no tenemos técnicas analíticas que nos permitan entenderlo. Recuerda, no es lo mismo entender la relación entre dos o entre tres variables que entender la relaciones entre miles de variables. Otra cosa es que muchos expertos opinan que debe ocurrir algo parecido.
Una pregunta, un clon de esta máquina con el mismo entrenamiento de esta maquina y bajo los mismos movimientos del oponente ¿tendrá siempre la misma respuesta de juego? y si no es así, cual es el factor de aleatoriedad que impide la clonación de las respuesta para el clon de esta máquina. La gracia de la inteligencia biológica mas que la adaptación para resolver problemas es la imprevisibilidad de las soluciones que entrega.
Reneco, el algoritmo de Montecarlo usa números aleatorios para podar el árbol de juego a partir de las posiciones seleccionadas por la red neuronal. Por ello, si el oponente en dos partidas diferentes juega exactamente igual, AlphaGo repetirá algunas jugadas, pero no todas y jugará de forma diferente.
Lee Sedol lo sabía y por eso no jugó a «clonar» la cuarta partida durante la quinta.
Gracias, por la respuesta.
Una aclaración. Las partidas que se usaron para entrenar el policy network fueron de jugadores amateur.
Saludos
Santiago, como puedes leer en el artículo de Nature: «Policy network: We trained the policy network pσ to classify positions
according to expert moves played in the KGS data set. This data set contains 29.4 million positions from 160,000 games played by KGS 6 to 9 dan human players; 35.4% of the games are handicap games.»
Gracias Francis. Soy lego en esto, pero requiere el cerebro humano «muchos ejemplos» para aprender ? Si alguien que nunca ha visto un perro ve solamente uno hoy y se le dice que se trata de un perro, si mañana ve otro (aun de una raza, color, tamaño diferente al primero) creo que lo clasificará inmediatamente como perro.
Mi punto es que pareciera haber una enorme diferencia entre el aprendizaje tipo cerebro humano y el aprendizaje de las neuronas artificiales, específicamente en el número de ejemplos requeridos.
Saludos.
Efectivamente como comentas a día de hoy todavía existe una gran diferencia entre la forma de procesar información de nuestro cerebro con la de los algoritmos inteligentes. Nuestros algoritmos todavía no son capaces de sacar todo el partido a los datos que le suministramos. Esto ocurre en parte porque nuestros cerebros han evolucionado a lo largo de los años para especializarse en procesar la información del mundo en el que vivimos. Por ejemplo, evolutivamente hemos desarrollado mecanismos por los cuales se nos hace muy fácil entender la tridimensionalidad de nuestro entorno. O las físicas del mundo en el que vivimos. La evolución nos ha proporcionado las herramientas para poder contar con este conocimiento a «priori», por lo que cuando vemos una foto de un perro, podemos inferir una tridimensionalidad que nos permite extraer más conocimiento de los pocos ejemplos que se nos muestra. Por el contrario, una red neuronal convolucional, normalmente se entrena desde cero (partiendo de estados aleatorios), sin tener codificado en sus parámetros conceptos como la perspectiva, la profundidad o la física de lo que observa. Eso implica que necesitará de un mayor número de datos para su proceso de entrenamiento.
Dentro del Machine Learning, hay un campo muy activo que investiga algoritmos capaces de aprender en base a pocos ejemplos. A este campo de técnicas se le denomina «One-shot learning», por si te interesa conocer más. Un saludo!