

La contratación, promoción y financiación de los científicos excelentes se basa en métricas de impacto y productividad. Los más productivos suelen tener mayor impacto. ¿Se puede separar la productividad del impacto? Un nuevo artículo propone usar clones de científicos. Para evaluar a un científico con cierta producción se construye un clon (científico promedio) con la misma producción en su área de conocimiento (para ello se usan datos estadísticos); al comparar el impacto del científico con su clon se puede estimar su grado de excelencia.
Lo más curioso es que el nuevo método puede ser aplicado a cualquier métrica bibliométrica o cienciométrica. La excelencia se mide gracias a la diferencia para dicha métrica entre el científico y su clon (el valor z es la diferencia entre los valores medios normalizada por la desviación típica). Si eres aficionado a la bibliometría, te recomiendo leer a Jasleen Kaur et al., «Impact, productivity, and scientific excellence,» arXiv:1411.7357 [cs.DL].

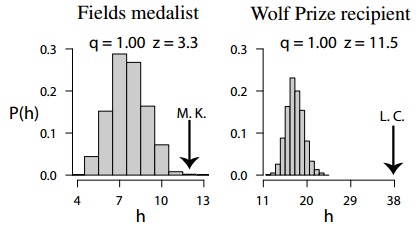
Esta tabla muestra la excelencia científica medida con el valor z para el índice h de Hirsch de premios Nobel en diferentes áreas. Muchos de ellos tienen puntuaciones z altas, pero índices h bajos. Las comparaciones son odiosas y no me quiero sacar conclusiones apresuradas.
Las comparaciones son odiosas dice el dicho, y generalmente conducen a conclusiones equivocadas. Se comparan campos distintos con impactos distintos. No creo que este tipo de estudios conduzca a algún tipo de conclusión verificable. Pero pueden ser usados para determinar tendendencias.
Muy interesante, pero veo una pega importante que no sé si tú compartirás, Francis (también he de decir que lo he leído en diagonal). Si un set de papers (un investigador, por ejemplo) tiene una gran productividad en papers de bajo impacto, la asignación aleatoria de citas de su método hará que los papers de alto impacto queden diluidos en los clones, con lo cual, estos tendrán un h-index mucho más bajo que el investigador con alta probabilidad. Por tanto, esto nos lleva a que un investigador que publica mucho con poco impacto y algunos papers de más impacto se califique como «de excelencia».
Y, yéndonos al extremo, si un investigador publicase (poco o mucho, pero) homogéneamente todo artículos de gran impacto, esta métrica nos diría que es un investigador mediocre, puesto que sus clones tienen el mismo h-index que él. No parece muy sólida.
Iñaki, creo que te confundes. La idea de los clones no es que sean científicos con el mismo valor del índice bibliométrico (sea el índice-h), sino científicos que hayan publicado el mismo número de papers en los mismos años y en los mismos temas que el científico considerado. La distribución de clones permite obtener un valor medio y la desviación típica del índice bibliométrico (sea el índice-h), es decir, un científico «clon promedio» que se compara con el del científico.
Tu caso extremo, un científico que publique pocos artículos pero de gran impacto, sería un investigador muy excelente, pues hay muy pocos científicos que publiquen pocos artículos de gran impacto; todos los clones serían científicos con pocos artículos y su impacto promedio con toda seguridad sería muy bajo.
Saludos
Francis
Creo que me he explicado mal. Claro que la idea de los clones es que tengan la misma producción, no decía lo contrario. El punto está en cómo se calcula el parámetro de los clones. Si lo que queremos comparar es el h-index —y si no lo he entendido mal, este es el tema—, se hace sobre el mismo set de papers, pero las citas de cada artículo se muestrean entre los artículos (mismo año, misma disciplina) de ESE MISMO investigador. Es decir, se coge un set cerrado de papers, correspondientes a ese investigador, y se «remuestrean» las citas de cada uno sobre el mismo set. ¿Es esto correcto?
Si es correcto y he entendido bien, entonces un investigador que publique todo artículos de alto impacto, al «remuestrear» estas citas, todos los artículos tendrían el mismo número de citas, no cambiaría. Por tanto, el cálculo del h-index de un clon saldría igual que el del investigador y varianza nula. Por tanto, como la diferencia entre la media de clones y el investigador en el h-index es nula, tendríamos un «mal» investigador según esta métrica. Lo cual no tiene sentido porque, como bien dices, eso sería un investigador MUY excelente.