

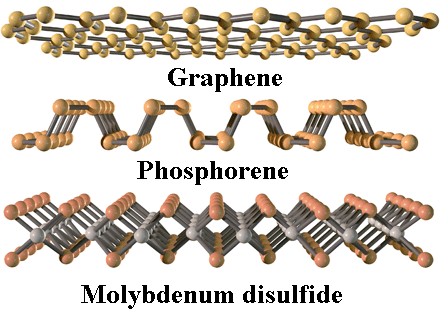
La revolución del grafeno es la revolución de los materiales bidimensionales. El grafeno es un semimetal y en muchas aplicaciones son preferibles los semiconductores planos como el fosforeno y el disulfuro de molibdeno. De hecho, que el grafeno no sea un semiconductor es su mayor inconveniente. Aún así, en el año 2014 se publicaron más de 15000 artículos sobre el grafeno. El número de artículos sobre los semiconductores planos está creciendo de forma exponencial, se publicaron en 2014 más de 1500 artículos sobre el disulfuro de molibdeno y casi 200 sobre el fosforeno.
Qué material plano será el que copará el mercado todavía no está decidido. No todas las apuestas están del lado del grafeno. Nos lo cuenta Robert F. Service, «Beyond graphene,» Science 348: 490-492, 01 May 2015, doi: 10.1126/science.348.6234.490.

En el campo de la micro y nanoelectrónica los materiales más prometedores son los semiconductores. Siendo un semimetal, los investigadores han tratado de transformar el grafeno en semiconductor. Hay varias opciones, pero ninguna acaba de convencer a los expertos. Esta inquietud ha llevado a centrar los esfuerzos en los semiconductores planos, como el fosforeno y el disulfuro de molibdeno. Todo apunta a que estos materiales dominarán el mundo de la nanoelectrónica, relegando al grafeno a un papel casi irrelevante. Más aún, en muchas aplicaciones donde el grafeno se suponía que era una apuesta firme hoy en día no se puede descartar que el siliceno, el germaneno o el estaneno acaben dando mejores resultados prácticos.
Por supuesto, el grafeno encontrará su nicho en el futuro de la nanotecnología. Por ejemplo, sus propiedades ópticas y optoelectrónicas son excepcionales. Hojas planas casi transparentes, flexibles pero de gran dureza, prometen revolucionar el campo de los pantallas flexibles para dispositivos móviles. En dicho campo el grafeno no tiene competencia.

El disulfuro de molibdeno (MoS2) plano fue sintetizado por primera vez en 2008. Un material abundante, barato y que no es tóxico, que como todos los dicalcogenuros de metales de transición, es un semiconductor (tiene un bandgap entre 1,3 eV y 1,9 eV según el tipo de monocapa; recuerda que el grafeno no tiene bandgap). Puede comportarse como material dador (tipo n) o aceptor (tipo p) de electrones. Además, su mobilidad de portadores (electrones en el tipo n y huecos en el tipo p) es alta, hasta 480 cm²/Vs, pero está por debajo del silicio cristalino, 1400 cm²/Vs, aunque por encima del silicio amorfo y otros semiconductores ultradelgados. Este es quizás su mayor inconveniente, aún así su futuro es prometedor.
Los primeros transistores de MoS2 se publicaron en 2011 (en Nature Nanotechnology). Usaban una monocapa con un grosor de 0,65 nm y mostraban una alta velocidad de conmutación. Su bandgap permite el desarrollo de dispositivos ópticos, como diodos emisores de luz, láseres, fotodetectores o incluso células solares.
El fosforeno (también llamado fósforo negro) es el gran rival del MoS2. Este alótropo del fósforo que muestra una estructura monocapa corrugada fue sintetizado por primera vez en 2014. Su mobilidad electrónica, casi 600 cm²/Vs, y su gran bandgap, que varía en función del número de capas entre 0,3 y 1 eV, lo convierte en un competidor difícil de batir. Su gran inconveniente es que es inestable en el aire. La solución es encapsularlo con una capa protectora de óxido de aluminio o de teflón. Siendo el material monocapa menos estudiado se esperan grandes avances en los próximos años.

Por último me gustaría recordar una cosa. Los materiales planos se pueden usar para diseñar heteroestructuras y superredes formadas por diferentes capas. Dicen que si no puedes con tu enemigo únete a él. Quizás el futuro de los semiconductores planos es la combinación de varios de ellos en el mismo dispositivo. El grupo del premio Nobel de Física André Geim presentó diodos LED de este tipo en febrero de este año (F. Withers et al., «Light-emitting diodes by band-structure engineering in van der Waals heterostructures,» Nature Materials 14: 301-306, 02 Feb 2015, doi: 10.1038/nmat4205).
Un gran artículo como siempre Francis, aunque según señalas los nuevos materiales tienen una movilidad(n) bastante menor que el silicio. Tenemos al típico Ga As que por otro lado tiene una movilidad(n) mucho mayor, aunque la(h) es menor; pero supone un alto coste a nivel de producción. ¿Crees que bajo el incremento de la demanda exponencial en transferencias de datos en la red(hd, 1080p), será más la necesidad comercial, que el hecho de las limitaciones físicas(nivel de integración de ICs(nm a 0, … nm) y problemas de electromigración(Hz)) lo que nos llevará hacia la optoelectrónica-fotónica?
Un saludo
Luis, ni idea, pero como decía un reciente Editorial en Nature («There’s more to come from Moore,» Nature 520: 408, 23 Apr 2015, doi: 10.1038/520408a) se acerca el límite físico del paradigma actual y habrá que cambiar de paradigma. Hay muchas propuestas en investigación, no sabemos cuál será la que se acabe llevando el gato al agua. No soy aficionado a este tipo de predicciones.
Saludos
Francis
Todo esto es siempre interesante, pero la pregunta real que hay que hacerse al final de la historia es ¿cuando alguna de esas tecnologías será rentable económicamente?
De poco nos sirve crear un circuito experimental en un laboratorio con un enorme coste. O mejor dicho, si que nos sirve (faltaría), pero sin una forma de hacer esos «cacharritos» en grandes densidades a precios económicos, esto se quedará (como tantas cosas) .
De hecho estamos bastante cerca ya de los límites del silicio. Las generaciones actuales andan por los 14 nanometros. Obviamente no podemos ir bajando continuamente, pero si que hasta que este tipo de materiales sean «rentables» (no solo rentables, sino que sepamos hacer chips complejos con ellos) me temo que deberemos de pensar en cambios de arquitectura de uno u otro tipo, como apilar en 3D (que ya algo se hace) y cosas por el estilo.
Un cambio de tecnología es algo que no se hace a la ligera, entre otras razones por el inmenso coste que supone. Un simple cambio de proceso (por ejemplo de 22 nm a 17 nm) ya implica unos costes surrealistas en la producción en forma de cambios en las cadenas de fabricación. Uno que implique un cambio radical implicaría prácticamente crear «desde cero» nuevas plantas de fabricación de chips, con tecnologías nuevas (y no demasiado probadas) y para los inversores es un riesgo enorme, de manera que me da la impresión de que hasta que alguna de esas tecnologías esté «clara» el mercado va a inclinarse por otro tipo de soluciones, como aumentar los nucleos y cambiar el tipo de programación a una mas «en paralelo», repartir cargas de proceso y soluciones por el estilo.
Eso si, el que se lleve el «gato al agua» va a conseguir unos beneficios surrealistas
Interesante lo que dices Orbatos, de hecho creo recordar artículos en los que se decía que la rentabilidad de los últimos procesos de fabricación FinFet a 14 nm está alcanzando su límite. También creí leer que a su vez tampoco hay una clara mejoría en cuanto a la disminución de superficie en los últimos saltos en cuanto a litografía. ¿Quizás Francis sepa más de estos temas? Lo que si parece claro es que la potencia de los dispositivos si que se sigue reduciendo y es espectacular que tengamos por ejemplo i7s de última generación que consuman 20 W o incluso menos, frente a los 80 W , etc de hace sólo unos pocos años. Si hubiese sido posible mantener esta tendencia podríamos llegar a bajar de 1W para un procesador tope de gama de última generación, lo que habría sido realmente espectacular.
Por otro lado, en cuanto al aumento de los núcleos, recuerdo una charla de un profesor de la UMA que trabajaba con nVIDIA. Igual Francis lo conoce, que nos hablo sobre la dudosa mejora de superar los 8 núcleos para una máquina estándar (no los servidores). Y los problemas que había a la hora de implementar buenas soluciones para un PC normal que usasen CUDA u otros lenguajes por el estilo para sacar mayor provecho al procesador.
El paralelismo «estilo» CUDA no es de propósito general porque todos los núcleos ejecutan exactamente el mismo código. El problema de usar múltiples hilos de ejecución en la práctica y básicamente, son de coste de programación; excepto contextos muy específicos (ej. SQL, procesamiento de imágenes, código puntual que admita OpenCL, mathematica y otros que usan funciones/api ya paralelizadas) hacer una aplicación que utilice múltiples hilos es costosa, no sólo por la codificación en sí (ej. en Haskell es trivial paralelizar ciertos códigos) sino porque una distribución adecuada en función de la memoria e hilos disponibles es, en general, difícil de conseguir. Es decir, para una buena paralelización hay que «tunear» el código en función de si tendremos mucha o poca memoria y muchos o pocos procesadores. Así, las aplicaciones suelen tender (en el mejor de los casos cuando están bien hechas) a realizar operaciones asincrónicas (ej. a la vez que genero la escena a renderizar voy calculando la física del siguiente frame), en el que unos cuantos procesadores (4, 8, 16, …) pueden ser aprovechados, pero en los que difícilmente servirían muchos más (32, 64, …). Resumiendo, excepto en los ámbitos antes mencionados, no existe (que yo sepa) ningún lenguaje/compilador que escale automáticamente la paralelización de un programa por tanto, debe hacerse a mano «y con cuidado».
Por ejemplo, sumar todos los enteros existentes en las hojas de un árbol binario es trivialmente paralelizable en Haskell haciendo `add (Leaf x) = x; add (Node l r) = a `par` b `pseq` (a + b) where (a, b) = (add l, add r)` sin embargo y un cuando el código efectivamente usará todos los procesadores disponibles (sean 1 o 1000) el rendimiento para (x ej) 4 procesadores es desastroso (de hecho peor que usar sólo 1) que un código adhoc.
Luis, supongo que sería Manuel Ujaldón http://cms.ac.uma.es/ujaldon/index.php/es
Si se me permite el comentario.
Es un hecho conocido, no todos los algoritmos son susceptibles de procesarse de forma paralela, no obstante otros si que lo son. Lo que se debe de intentar es aumentar el uso de esa potencia disponible, y sobre todo mejorar el uso de los recursos.
Es paradójico, que hoy en día si quieres disparar la percepción de potencia de un equipo, el cambiar de un procesador de 4 núcleos a uno de 8 no te va a dar una impresión muy evidente (y es normal). En cambio, cambiar tu disco mecánico por uno sólido dispara ese rendimiento de una forma muy evidente.
La carrera tecnológica sin duda es importante, pero estamos llegando a un punto donde hay que empezar a plantearse (al menos hasta que tengamos nuevos materiales comercialmente convenientes) si no deberíamos de «cambiar el chip» de otro modo.
El mayor problema en maquinas domesticas (que no supercomputadores, ese es otro tema) son los cuellos de botella, los ciclos en los que un componente no hace nada porque está esperando a otro. La arquitectura de los ordenadores no ha cambiado de forma muy significativa desde hace muchos años. Ahora son mas pequeños, mas rápidos, con mas núcleos, menos consumo, etc.
Pero, si se me permite la similitud, es como si inicialmente andaramos montados en un burro, y con el tiempo hemos refinado ese equino hasta el equivalente moderno de un pura raza árabe, o un percherón dependiendo del tipo de trabajo a realizar, pero seguimos montando a caballo. Lo mismo algunas soluciones pasan por repensar la forma en la que se organiza la arquitectura de esas máquinas para aumentar su rendimiento aprovechando lo que tenemos, antes que limitarnos a aumentar la fuerza bruta.
Un ejemplo de lo que quiero decir, se podría encontrar en algunas placas modernas (hablo a nivel domestico, que es otro mercado) que integran puertos para dispositivos de almacenamiento con un ancho de banda enorme. El ordenador obviamente «corre mucho mas», pero no por tener un procesador superchulo con sopotocientos megahercios, sino porque se ha modificado el modo en que algunas partes de ese ordenador se comunican entre si.
Ahora estamos en buena medida en la revolución del almacenamiento, y parte de esa revolución es saltarnos la idea clásica de que los dispositivos de almacenamiento «son lentos», y eso obliga a cambiar la forma de pensar las cosas. Falta ver a donde nos llevará esto, pero creo que los aumentos de potencia mas importantes probablemente vengan en los próximos tiempos por ese camino.
Parece que de momento hasta los 7 nm van a llegar:
http://www.conocedell.es/noticias/como-puede-intel-prolongar-la-ley-de-moore
Muy interesante la noticia y vuestros comentarios.
Al hilo de lo que comenta Orbatos sobre máquinas domésticas, que ofrecen un mercado potencial para los próximos anhos muy alto, tenemos la tecnología 22nm FDX anunciada hace poco por Globalfoundries, antigua AMD, que recientemente ha adquirido tecnología de IBM. Tecnología en parte, pensada para productos de bajo consumo y mucha autonomía, conceptos como IoT, internet of things, que será la tecnología del futuro próximo probablemente.
Aquí un enlace sobre 22nm FDX: http://globalfoundries.com/docs/default-source/PDF/22fdx-product-brief.pdf?sfvrsn=10
¿ Cuántos tipos de materiales de tipo grafeno, se han estudiado hasta la fecha, aparte del grafeno ( C ), siliceno ( Si ), staneno ( Sn ) y fosforeno ( P ), monocapa ?
Hay decenas de materiales bidimensionales, Horch, pero muchos son moleculares (grafano, MoS2, h-BN, g-C3N4, WSe2, ReS2, InSe, etc.) en lugar de atómicos (borofeno, germaneno, antimoneno, etc.).
Infinidad. Busca en google scholar. Algunos ejemplos super conocidos: Graphene silicene germanene BN MoX2 (X=Se, S, Te), InX, etc
Es curioso, al calcular el bangap de los materiales 2D elementales ( borofeno, alumineno, indianene, grafeno, siliceno, germaneno, fosfórico, arsénico, … ), me salen unas cosas, y luego, según he visto en otra tabla, los resultados son otros. ¿ Por qué será ?.
Material IP EA Eg = IP – EA Eg exp Tipo
B 8.3 0.28 8.02 0 metal
Al 5.99 0.46 5.53 0 metal
Ga 6.0 0.3 5.7 0 metal
In 5.8 0.3 5.5 0 metal
Tl 6.1 0.3 5.8 0.14 semimetal
C 11.26 1.27 9.99 0 semimetal
Si 8.15 1.39 6.76 0.01 semimetal
Ge 7.9 1.2 6.7 0.02 semimetal
Sn 7.34 1.25 6.09 0.07 semimetal
Pb 7.42 0.37 7.05 0.42 semiconductor
P 10.49 0.74 9.75 1.67 semiconductor
As 9.8 0.8 9 0.90 semiconductor
Sb 9,01 1.97 7.59 0.28 semiconductor
Bi 8.42 0.95 7.47 0.32 semiconductor
Se 9.75 2.02 7.73 0.75 semiconductor
Te 9.01 1.97 7.04 7.04 semiconductor
Según la teoría de Robert Mulliken Eg = IP -EA
5.5 a 8.02 metal
5.8 a 9.99 semimetal
7.05 a 9 semiconductor
Horch, no entiendo tu pregunta o comentario. ¿Al calcular cómo? ¿Usando la teoría fenomenológica de combinación lineal de orbitales atómicos de Mulliken? No entiendo.
Según la teoría de Mulliken, es posible calcular la banda de energía prohibida, restando al potencial de ionizacion ( IP o I ), la electro afinidad ( EA o A ), quedando Eg = IP – EA. La energía de Fermi o potencial químico ( μ ) quedaria: EF = μ = IP + EA / 2. https://www.researchgate.net/publication/350968708_Understanding_How_Lewis_Acids_Dope_Organic_Semiconductors_A_Complex_Story
También he utilizado una aproximación a las ecuaciones de Drude, más sencillas:
n = ( Z/A ) n° ; siendo Z: num. De electrones de valencia; A, la masa atomica y n°, el número de átomos por celda
EF ~ n
Eg = 2EF
Dandome:
Material 2D —– Eg ——- Eg real ——– Material 2D ——- Eg ———–Eg real ———– Material 2D —– Eg ——Eg R
B ——————– 1, 1098 —- 0 ——— Si —————— 0, 5696 ——0,01 ———- P ————–0, 6456 ——1, 67
Al ——————— 0, 4446 —- 0 ——— Ge —————–0,2202 ——–0,02 ———- As ———— 0, 2668 ——0, 90
Ga ——————–0, 172 ——- 0 ——— Sn —————–0, 1346 ——–0, 07 ——— Sb ———– 0, 1642 ——0, 28
In ———————- 0, 1044 —- 0 ——— Pb —————- 0,0772 ——– 0, 42 ——— Bi ———— 0, 0957 —– 0, 32
Tl ———————-0, 0586 —–0, 14 ——— Se —————- 0, 3038 ——- 0, 75
C ———————–1, 332 —— 0 ——— Te —————– 0,094 ———- 1, 13
También he visto en otros apuntes: lF ~ 1/g(EF); g(EF) ~ 1/lF; siendo: lF the mean free path of the electron, y g(EF), la densidad de estados. La velocidad de Fermi, vF ~ 1/ ( g(EF)1/2 ; y EF ~ vF2/2
Elemento 2D —– radio atómico ( A° ) —-n°A —– πr2 —–lF —– — g( EF ) ——vF2 ———- EF ———–Eg —— Eg real
————————————————————————-1/n°πr2—————1/lF———1/g(EF)—-vF2/2——–2EF—————–
——B ————————-2,05———————–2 ——-13, 202—0,0378—26,455—–0,0378—0,0189—-0,0378———0—-
——-Al————————-2,39———————- 2 ——-17, 944—0,0278—35,971—–0,0278—0,0139—–0,0278——–0—-
——-Ga———————–2,33———————–2——–17,054—–0,0293—34,129—–0,0293—0,0146—–0,0292——–0—–
——-In————————2,46———————–2———19,011—–0,0263—38,022—–0,0263—0,0131—-0,0262——–0—–
——-Tl————————2,42———————–2———18,397—–0,0271—36,900—–0,0271—0,0135—-0,027———-0,14–
——-C ————————1,90———————–2———11,340—–0,0440—22,727—–0,0440—0,022——0,044———-0——
——-Si————————2,32———————-2———-16,908—–0,0295—-38,898—-0,0295—-0,0147—-0,0294——-0,01—
——-Ge———————-2,34———————-2———–17,201—–0,0290—-34,482—-0,0290—-0,0145—-0,029———0,02—
——–Sn———————2,48———————-2———–19,321—–0,0258—-38,759—-0,0258—-0,0129—–0,0258——-0,07———-Pb——————–2,49———————–2———–19,468—–0,0256—-39,062—-0,0256—-0,0128—–0,0256——-0,42—
——–Se——————–2,24———————-2————15, 762—–0,0317—31,545—–0,0317—-0,0158—–0,0316——0,75—
——–Te——————–2,42———————-2————18,397——0,0271—36,900—–0,0271—-0,0135—–0,027——–1,13—
——–P———————2,23———————-2————15,622——0,0640—-15,625—–0,064—–0,032——-0,064———1,67–
——–As——————-2,31———————-2————-18,222—–0,0274—-36,496—–0,0274—-0,0137—-0,0274——–0,90-
——-Sb——————–4,46———————-2————-62,489—–0,0080—-125———-0,008——0,004——0,008———-0,28-
——-Bi———————2,50———————2————–19,634—-0,0254—–39,370—–0,0254—-0,0127—-0,0254——–0,32-
Cómo lo calculaste?? Usaste DFT? En este caso si usaste un funcional GGA tipo PBE ni de lejos se parecerá a «esa otra tabla». Ésta eranvalores experimentales? De qué tecnica? Si has aplicado DFT, HOMO (en este caso banda de valencia) no es el IP. Igual para la AE. Veo comentarios «poco cientificos…..»