


En 2011 nació el aprendizaje automático antogónico (AML, siglas de Adversarial Machine Learning). En 2014 nacieron las redes generativas antagónicas (GAN, siglas de Generative Adversarial Networks). Pero quizás lo ignorabas hasta que en diciembre de 2018 NVIDIA te dejó con la boca abierta con un espectacular vídeo en YouTube. Un generador automático de caras humanas hiperrealistas basado en redes generativas antagónicas. A partir de dos caras iniciales se genera una nueva cara, con otro color de piel, de cabello, con un nuevo peinado o una nueva pose. Y todo ello mediante un algoritmo no supervisado. ¡Increíble, pero cierto!
El AML nació para lograr que los modelos de aprendizaje automático fueran robustos frente a ejemplos antagónicos: imágenes con mucho ruido, aunque indistinguibles del original para el ojo humano, que producen una respuesta incorrecta. Las GAN implementan esta idea usando dos redes de neuronas artificiales (generadora G y discriminadora D) que compiten entre sí en un juego. La generadora combina ruido y datos reales de entrada para generar nuevos datos sintéticos. La discriminadora trata de distinguir entre entradas reales y sintéticas. Las dos redes compiten de tal forma que la generadora intenta generar mejores entradas sintéticas, mientras que la discriminadora trata de distinguirlas lo mejor posible. El juego acaba cuando se alcanza un equilibrio entre ambas. El resultado final en el generador de caras sintéticas de NVIDIA es asombroso.
Te recomiendo ver el vídeo más abajo (aunque casi seguro que ya lo has visto). El artículo de NVIDIA es Tero Karras, Samuli Laine, Timo Aila, «A Style-Based Generator Architecture for Generative Adversarial Networks,» arXiv:1812.04948 [cs.NE]; las GAN nacieron en Ian J. Goodfellow, Jean Pouget-Abadie, …, Yoshua Bengio, «Generative Adversarial Networks,» arXiv:1406.2661 [stat.ML]; y el AML en Ling Huang, Anthony D. Joseph, …, J. D. Tygar, «Adversarial machine learning,» AISec ’11 Proceedings of the 4th ACM workshop on Security and artificial intelligence, pp. 43-58 , doi: 10.1145/2046684.2046692. Recomiendo leer también a Saifuddin Hitawala, «Comparative Study on Generative Adversarial Networks,» arXiv:1801.04271 [cs.LG].
Este vídeo de NVIDIA requiere pocas explicaciones. Por ahora solo se generan caras hiperrealistas, pero en un futuro no muy lejano se generarán actores virtuales de cuerpo entero. Sin lugar a dudas estamos ante una gran revolución en la industria multimedia.

Esta figura ilustra la idea conceptual de las GAN profundas convolucionales (DCGAN, siglas de Deep Convolutional Generative Adversarial Networks). En términos matemáticos, la red convolucional discriminadora es una función D(x) que devuelve la probabilidad de que la entrada x sea real y la red convolucional generadora es una función G(z) que recibe como entrada un vector aleatorio z generando una entrada sintética. El entrenamiento no supervisado de ambas redes se realiza de forma simultánea teniendo como objetivo que D(G(z)) devuelva una probabilidad de 1 (uno) para imágenes reales y de 0 (cero) para imágenes sintéticas. En teoría ambas redes participan en un juego mini-max dado por la función que aparece en la figura. Para pocas capas (pongamos 4 capas en cada red) los resultados son pobres y las imágenes resultado están muy lejos de ser realistas.
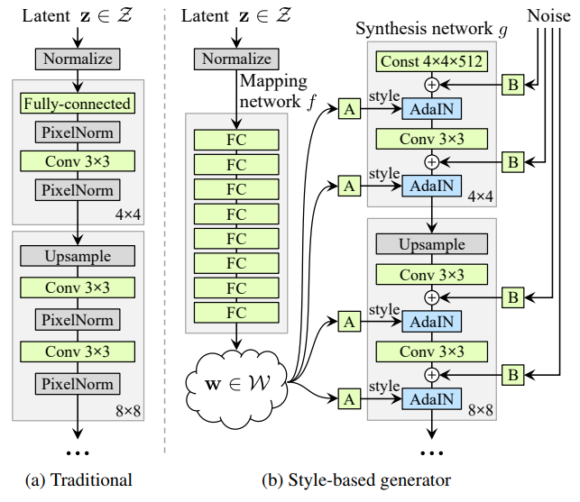
La nueva DCGAN de NVIDIA usa 8 capas para la red discriminadora y 18 capas para la red generadora (dos capas para cada resolución desde 4×4 píxeles hasta 1024×1024 píxeles, siendo la salida de la última capa una imagen RGB de un megapíxel). Hay 26.2 millones de parámetros cuyo valor cambia durante el entrenamiento. En lugar de usar la técnica de entrenamiento convencional en las GAN se ha usado una nueva técnica (mostrada en esta figura), llamada entrenamiento guiado por el estilo (en referencia a peinado, pose, etc., de la cara).

En las redes de aprendizaje profundo el tamaño importa, y mucho. La DCGAN de NVIDIA ha sido entrenada con 25 millones de imágenes de caras humanas. Gracias a un conjunto tan grande se han obtenido unos resultados que rayan con lo imposible. Las caras sintéticas generadas son casi indistinguibles de una fotografía.

Por cierto, también se ha entrenado el algoritmo con 70 millones de imágenes de camas de dormitorio (BEDROOMS), otras tantas fotos de gatos (CATS), y 46 millones de fotos de automóviles (CARS). Los peores resultados se han obtenido con los gatos, quizás por la gran variabilidad en su pose corporal y en su entorno. Ya se sabe que los gatos son de carácter inquieto.
En resumen, un buen ejemplo de lo que están avanzando las técnicas de aprendizaje profundo en el campo de la síntesis y análisis de de imágenes. Falta mucho para que estas técnicas dominen la síntesis fotorrealista de imágenes, pero tiempo al tiempo. Mientras tanto podemos conformarnos con disfrutar de sus resultados. ¿No has visto el vídeo aún? ¡A qué esperas!
Amazing
Gracias Francis!. Después de leer la entrada me quedo más tranquilo en cuanto a la capacidad de la IA, quiero decir el peligro de la IA, porque la idea que me queda es que el generador de caras sigue siendo una «máquina tonta», como la calculadora de bolsillo que hace cálculos asombrosos en un instante pero sigue siendo una máquina sin consciencia. El problema es el bicho humano; no creo que esté dando ideas si digo que esto se usará para falsificar identidades. El probelma no es que la IA se haga con el control de los humanos sino que ciertos humanos se hagan con el control de la IA
Sin entrar en si esta tecnología servirá para «fabricar» fake news (*) o lo que sea, me quedo con el mérito científico y técnico de sus desarrolladores. Es algo alucinante.
(*)
https://www.youtube.com/watch?v=LVuo_DyAf2g#t=3m23s