

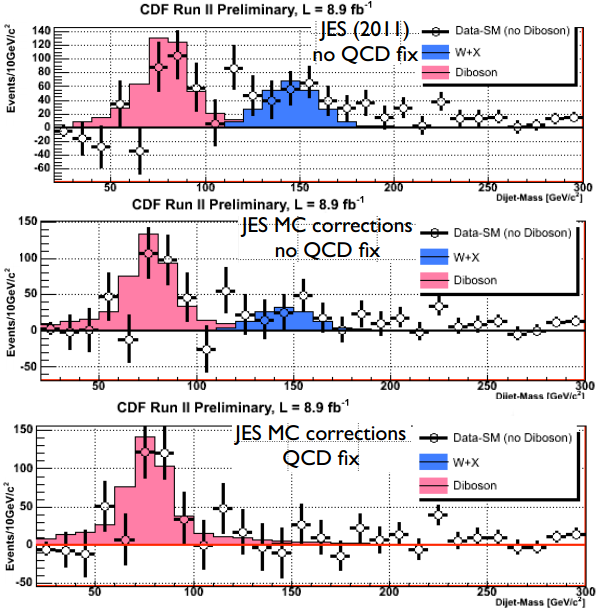
Se han ofrecido muchas explicaciones para la anomalía W+jj observada en los datos del experimento CDF del Tevatrón en el Fermilab, cerca de Chicago. El otro experimento del Tevatrón, DZero no observó dicha anomalía; CMS y ATLAS del LHC en el CERN tampoco la observaron. Por tanto, la causa debe ser un «error sistemático» en los análisis de este tipo de colisiones. Ha costado dos años de intenso trabajo, basado en tres posibles hipótesis, hasta que se ha descubierto la razón. La técnica de Monte Carlo utilizada para el ajuste de los disparadores (triggers), utilizados en la identificación de los chorros, confunde cierto tipo de ruido de fondo con «supuestos» leptones (fake leptons), sobre todo electrones; reajustando la técnica de selección de eventos la anomalía W+jj desaparece y los datos corresponden a las predicciones del modelo estándar. Dos años de esfuerzos que han valido la pena. Había que encontrar el origen de este «error sistemático» pues podría afectar a otros análisis. ¿Afecta este cambio a otros análisis, como los del quark top o los del Higgs? El efecto es muy pequeño, despreciable en la práctica; así que no será necesario corregir los resultados publicados debido a la identificación errónea de los «supuestos» leptones. Nos cuenta la historia con detalles técnicos M. Trovato (on behalf of the CDF collaboration), «Update on dijet mass spectrum in W + 2jets events,» Wine & Cheese Seminar, Fermilab, Feb 23, 2013. El artículo técnico todavía no ha sido publicado en ArXiv, pero ha sido enviado a Physical Review D.
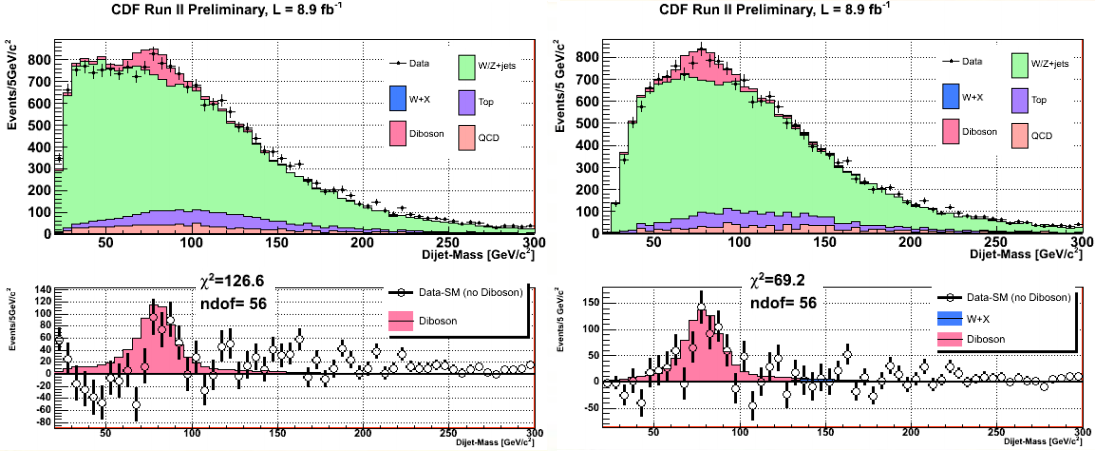
Estas dos figuras comparan el resultado previo (a la izquierda) y el nuevo (a la derecha). Ambas figuras están basadas en los mismos datos de colisiones (8,9 /fb ppbar en el Tevatrón), lo único que ha cambiado es la técnica de análisis (en concreto la técnica de identificación de los chorros cuando aparecen leptones). Como se ve, para valores pequeños de la masa invariante para las parejas de chorros (eje horizontal) se observan grandes diferencias entre ambas figuras. Esas diferencias son las grandes responsables de la anomalía que se había observado en los datos y que se publicó en 2011. Como ya viene siendo habitual, el modelo estándar es robusto, muy robusto.