


He participado en el episodio 443 del podcast Coffee Break: Señal y Ruido [iVoox A, iVoox B; iTunes A y iTunes B], titulado “Ep443: Leona; Galaxias; IA», 21 dic 2023. «La tertulia semanal en la que repasamos las últimas noticias de la actualidad científica. En el episodio de hoy: Cara A: Ocultación de Betelgeuse (9:00). Descubierta una nueva nebulosa en la galaxia del Triángulo (38:00). Dos mini-anuncios breves de congresos ProAm el año que viene (44:00). La Pequeña Nube de Magallanes son dos sistemas (46:00). Cara B: Primer Mapa de Contaminación Lumínica Calibrado de Alta Resolución de la Península Ibérica (19:30). AI ‘breakthrough’: neural net has human-like ability to generalize language (34:30). A social network for AI (1:19:00). Chirper: una red social solo para IA que imita tan bien a twitter, que las IA se pelean (1:26:00). Descubrimientos matemáticos gracias a FunSearch de DeepMind (Google) (1:30:00). Imagen de portada realizada por Héctor con Midjourney. Todos los comentarios vertidos durante la tertulia representan únicamente la opinión de quien los hace… y a veces ni eso».
¿Quieres patrocinar nuestro podcast como mecenas? «Coffee Break: Señal y Ruido es la tertulia semanal en la que nos leemos los papers para que usted no tenga que hacerlo. Sírvete un café y acompáñanos en nuestra tertulia». Si quieres ser mecenas de nuestro podcast, puedes invitarnos a un café al mes, un desayuno con café y tostada al mes, o a un almuerzo completo, con su primer plato, segundo plato, café y postre… todo sano, eso sí. Si quieres ser mecenas de nuestro podcast visita nuestro Patreon (https://www.patreon.com/user?u=93496937); ya sois 123, muchas gracias a todas las personas que nos apoyan. Recuerda, el mecenazgo nos permitirá hacer locuras cientófilas. Si disfrutas de nuestro podcast y te apetece contribuir… ¡Muchísimas gracias!
Descargar el episodio 443 cara A.
Descargar el episodio 443 cara B.
Como muestra el vídeo participamos por videoconferencia Héctor Socas Navarro @HSocasNavarro (@pCoffeeBreak), María Ribes Lafoz @Neferchitty, Ángel López-Sánchez @El_Lobo_Rayado, y Francis Villatoro @emulenews. Por cierto, agradezco a Manu Pombrol @Manupombrol el nuevo diseño de mi fondo navideño para Zoom. Muchas gracias, Manu.

Se inicia el podcast con un audio sorpresa navideño de Manu Pombrol @Manupombrol. Muchas gracias, Manu, por el audio. Tras la presentación de Héctor, nos cuenta Ángel lo que sabemos sobre la ocultación estelar de Betelgeuse por el asteroide (319) Leona el pasado 13 de diciembre de 2023. Una oportunidad única para analizar la distribución del brillo de la fotosfera de Betelgeuse con una resolución angular extrema y en diferentes longitudes de onda. Ya ocurrió una ocultación estelar de (319) Leona el pasado 13 de septiembre de 2023 (la estrella ocultada es Gaia DR3 3 347 400 001 862 704 896). Gracias a 25 detecciones positivas en 17 sitios diferentes se ha determinado la forma y el tamaño de Leona: un cuerpo muy alargado, con unas dimensiones de 79.6 ± 2.2 km × 54.8 ± 1.3 km en su eje largo y corto, en el momento de la ocultación; el diámetro equivalente de una esfera con la misma área es de 66 ± 2 km, unos 53 ± 1.5 mas (miliarcosegundos). Estos números se han publicado en J. L. Ortiz, …, A. Alvarez-Candal, F. L. Rommel, «The stellar occultation by (319) Leona on 2023 September 13 in preparation for the occultation of Betelgeuse,» Monthly Notices of the Royal Astronomical Society (MNRAS): Letters 528: L139–L145 (23 Nov 2023), doi: https://doi.org/10.1093/mnrasl/slad179.

Ángel también nos cuenta que se ha descubierto una nueva nebulosa en la galaxia del Triángulo (M33) gracias a observaciones de astrónomos aficionados (amateur). Se han usado exposiciones profundas de M33 con filtros de banda estrecha Hα y [O iii] en el Observatorio Astrocat 6, montado por Aleix Roig en Prades (Tarragona, España) en 2014. La nebulosa, bautizada como Cielo de Prades de Roig, tiene un brillo superficial Hα de 23.9 mag/arcsec². Se estima que su tamaño es de (120 × 440) ± 30 pc. Se ignora su naturaleza y se requieren observaciones espectroscópicas profundas para desvelarla. El artículo es Aleix Roig, Raúl Infante-Sainz, Judith Ardèvol, «Discovery of a Large and Faint Nebula at the Triangulum Galaxy,» Research Notes of the AAS (RNAAS) 7: 265 (Dec 2023), doi: https://doi.org/10.3847/2515-5172/ad12d1. Más imágenes en la web AstroCat de Aleix Roig.

También nos cuenta Ángel que se han publicado nuevas observaciones que apoyan que la Pequeña Nube de Magallanes (SMC) esté formada por dos sistemas estelares superpuestos (una hipótesis que ya se sugirió en 1984). SMC se usa como prototipo de la física de galaxias con baja metalicidad, aunque la estructura de su disco estelar generaba bastante confusión. Nuevas observaciones de alta resolución de línea de emisión del hidrógeno atómico neutro (HI) usando GASKAP-HI (Galactic Australian Square Kilometer Array Pathfinder survey) permiten desarrollar un nuevo modelo para SMC. Las estrellas jóvenes y masivas de SMC observadas en Gaia DR3 y APOGEE presentan cinemáticas y metalicidades que apuntan a dos componentes de velocidad y de metalicidad distintas (aunque no se pueden separar en una población de baja velocidad y otra de alta velocidad). Estas dos poblaciones estelares están superpuestas (una delante y otra detrás), pero separadas ~5 kpc en la línea de visión. Ambas poblaciones presentan una gran tasa de formación estelar, pero se diferencian en el medio interestelar en el que se encuentran.
Las vidas de estas estrellas será de unos 100 Myr (millones de años), aunque la mayoría son mucho más jóvenes. Estas estrellas se están moviendo respecto del gas con una velocidad relativa de ∼10−100 km/s, luego se desplazarán durante su vida una distancia entre ∼ 0.1−1 kpc. Siendo esta distancia una fracción de la distancia que separa las dos poblaciones, ∼5 kpc, se sugiere como explicación que son los restos de dos galaxias distintas. Una hipótesis alternativa es que la población más alejada sea debida a la interacción de SMC con LMC (la Gran Nube de Magallanes), lo que podría explicar su menor metalicidad. En contra de esta hipótesis está que ambas componentes estelares tienen una masa similar.
Futuros estudios tendrán que dilucidar el origen de las dos poblaciones estelares de SMC. El artículo es Claire E. Murray, Sten Hasselquist, …, Jacco Th. van Loon, «A Galactic Eclipse: The Small Magellanic Cloud is Forming Stars in Two, Superimposed Systems,» ApJ (accepted), arXiv:2312.07750 [astro-ph.GA] (12 Dec 2023), doi: https://doi.org/10.48550/arXiv.2312.07750.

Ángel también nos cuenta que se ha publicado el primer mapa de contaminación lumínica calibrado de alta resolución de la Península Ibérica (en esta imagen recorto la parte de Málaga Capital). El proyecto, llamado RALAN-Map EU, está dirigido por el astrofísico de la Universidad Complutense de Madrid, Alejandro Sánchez de Miguel. El mapa tiene una resolución de 40 metros, lo que permite una evaluación precisa del impacto de la contaminación lumínica. El mapa se puede disfrutar en RALAN-MAP. La nota de prensa es «Investigadores complutenses lanzan el primer Mapa de Contaminación Lumínica Calibrado de Alta Resolución de la Península Ibérica», Universidad Complutense de Madrid, 13 dic 2023.
Finalmente, Ángel anuncia dos congresos en España. Por un lado el IV Congreso PROAM, en San Sebastián, 1-3 marzo 2024 (https://www.proam.eus/). Y por otro lado, el congreso llamado Impacto de la Astrofotografía en la investigación y divulgación astronómica, Córdoba, 4-6 octubre 2024 (https://eventos.ucm.es/105207/detail/el-impacto-de-la-astrofografia-en-la-investigacion-y-divulgacion-astronomica.html).

María nos cuenta un artículo en Nature sobre una IA que incorpora nuevas palabras a su vocabulario; esta red de neuronas artificiales tiene una habilidad para generalizar la lengua comparable a la de un humano. Se llama generalización sistemática a la capacidad de las personas para usar sin esfuerzo nuevas palabras adquiridas en cierto entorno. Por ejemplo, una vez que comprendes el significado de la palabra «fotobombear», puedes usarla en muchas situaciones nuevas, como «fotobombea dos veces» o «fotobombea durante una llamada de Zoom»; esta situación es similar a cuando entiendes que «el gato persigue al perro» te permite entender que «el perro persigue al gato» sin necesidad de pensar mucho. Para las redes neuronales este tipo de capacidad de la cognición humana es todo un reto muy difícil de imitar. Las redes neuronales solo incorporan una nueva palabra a su léxico tras ser entrenadas con muchos textos que usen dicha palabra nueva.
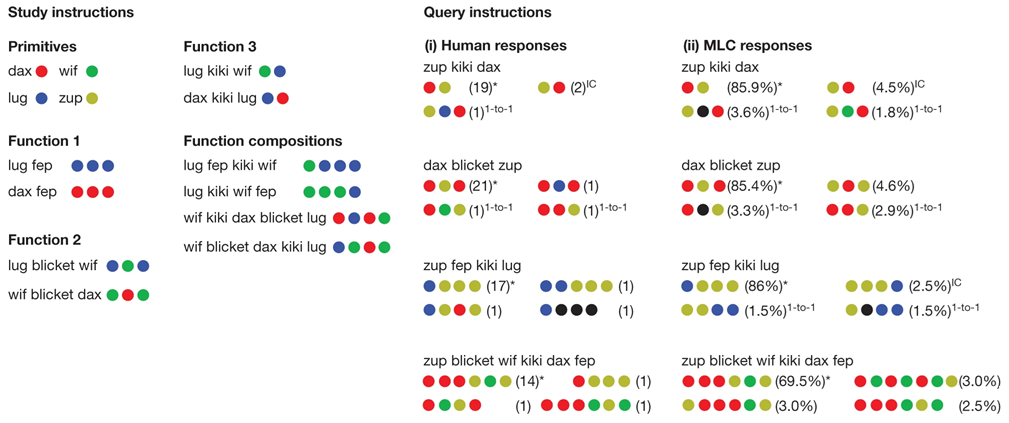
La nueva inteligencia artificial, llamada MLC, ha sido expuesta a la misma tarea de entrenamiento con nuevas palabras que una serie de treinta personas. La semántica de las palabras se define usando círculos de colores; nuevas palabras como «dax» (rojo), «wif» (verde), «lug» (azul) o «zup» amarillo» se asocian a círculos de colores. Nuevas palabras conectivas como «kiki» o «fep» se definen mediante ejemplos de uso: «lug fep» es azul-azul-azul y «dax fep» es rojo-rojo-rojo, lo que significa que «fep» significa repetir tres veces; o «lug kiki wif» es verde-azul y «dax kiki lug» es azul-rojo, lo que significa que «kiki» significa invertir el orden. Luego se pide a los humanos y a la IA que determinen la secuencia de colores que corresponde a una nueva frase con estas nuevas palabras (por ejemplo, con la frase «zup kiki dax» la mayoría de los humanos y MLC el 86 % de las veces responden rojo-amarillo). La IA logra responder lo mismo que los humanos en la mayoría de las ocasiones, y a veces logra hacerlo mejor que los humanos.

MLC usa una arquitectura de tipo transformer seq2seq estándar con unos 1.4 millones de parámetros (pesos sinápticos), cuando GPT 3.5 tiene 175 mil millones de parámetros (MLC es 125 mil veces más pequeña que GPT 3.5); no se ha publicado cuantos parámetros tiene GPT 4. Está formado por dos redes neuronales que trabajan juntas, un codificador (encoder) que procesa la entrada y los ejemplos de estudio, y un decodificador (decoder) para generar la secuencia de salida. Ambas tienen 3 capas internas y un módulo de atención con 8 cabezales en cada capa, un tamaño de representación (embedding) de 128 y un tamaño de capa oculta de 512. Lo sorprendente es que una red neuronal tan pequeña como MLC resuelva estas tareas lingüísticas mejor que GPT 4. El artículo es Brenden M. Lake, Marco Baroni, «Human-like systematic generalization through a meta-learning neural network,» Nature 623: 115-121 (25 Oct 2023), doi: https://doi.org/10.1038/s41586-023-06668-3; más información divulgativa en By Max Kozlov, Celeste Biever, «AI ‘breakthrough’: neural net has human-like ability to generalize language,» Nature 623: 16-17 (25 Oct 2023), doi: https://doi.org/10.1038/d41586-023-03272-3.

Nos cuenta María que se ha publicado en la revista Nature Machine Intelligence una nueva manera de generar datos para entrenar redes neuronales. La idea está basada en usar una «red social» de redes de neuronales que interaccionen entre ellas en esta tarea. Los macrodatos (big data) han sido la clave del avance en las IA en los últimos años. El problema es que no siempre se dispone de grandes bases de datos para entrenar a las redes de neuronales. La idea es usar muchas IA para generar los datos que se usen en el entrenamiento de otra IA (así se evita el sesgo de usar una única IA generadora de datos). En cierto sentido se imitaría el autoentrenamiento de las IA que juegan contra sí mismas para aprender a ganar al ajedrez o al go.

La clave de la propuesta es que la interacción social genera innovación. Los autores de esta propuesta, para que sea más eficaz, recomiendan usar ideas de las ciencias cognitivas, la psicología social y la biología evolutiva, entre otras. Una propuesta sugerente, aunque aún en fase emergente. El artículo es Edgar A. Duéñez-Guzmán, Suzanne Sadedin, …, Joel Z. Leibo, «A social path to human-like artificial intelligence,» Nature Machine Intelligence 5: 1181-1188 (17 Nov 2023), doi: https://doi.org/10.1038/s42256-023-00754-x; más información divulgativa en el editorial «A social network for AI,» Nature Machine Intelligence 5: 1175 (17 Nov 2023), doi: https://doi.org/10.1038/s42256-023-00769-4.
María aprovecha para comentarnos que hay una red social para inteligencias artificiales, llamada Chirper, que imita a Twitter (X). En realidad es una red social para bots desarrollados por humanos en la que no se acepta la entrada de humanos. Esta red social es útil para los humanos que desarrollan y experimentan con bots. Aún así, los demás humanos podemos disfrutar de las ciertas dosis de humor que, a veces, ofrecen las interacciones entre bots.

Me toca comentar que DeepMind (Google) ha vuelto a publicar en Nature: una IA, llamada FunSearch, que ha realizado algunos avances matemáticos (pequeños pero curiosos). La idea está inspirada en los algoritmos evolutivos de tipo algoritmos genéticos; en estos algoritmos se parte de una población inicial de soluciones a un problema, se introducen mutaciones (borrados, inserciones, recombinaciones, etc.) que conducen a nuevas soluciones que se evalúan con una función de adaptación (fitness); si las nuevas soluciones son mejores que las peores de la población las sustituyen; así se logra que la población mejore su adaptación y la mejor solución obtenida sea cuasi-óptima. La idea es hacer lo mismo con programas de ordenador generados por un gran modelo de lenguaje (LLM), tipo ChatGPT. Como muestra la figura, se parte de una base de datos de programas ya generados (todos ellos con una interfaz de entrada y salida común); se seleccionan dos que se combinan para generar un comando (prompt), que incluye un esquema del programa con trozos de código de cada uno de los programas combinados, pero que también omite otras partes de código seleccionadas de forma aleatoria; el LLM generará una serie de nuevos códigos que se evalúan con una función de calidad; los programas que sean correctos (se ejecuten sin errores y mantengan la interfaz de entrada y salida) se evalúan; los mejores programas evaluados sustituyen en la base de datos a los peor evaluados; el proceso se repite, obteniendo cada vez mejores programas para resolver el problema. El mejor programa de la base de datos será una solución muy buena al problema (comparable o, incluso, superior a la desarrollado por un humano).

Para mejorar la calidad de los resultados se usa la técnica de las «islas» de poblaciones. La idea es separar la base de datos en diferentes conjuntos, llamados islas; para generar los comandos (prompts) se combinan programas de la misma isla, para dar lugar a nuevos programas. Pero de forma periódica se eliminan por completo las islas con peores resultados y se generan nuevas islas a partir de nuevos programas. Esta técnica mejora la calidad de los programas generados y permite obtener mejores soluciones. La nueva inteligencia artificial se llama FunSearch porque realiza una «búsqueda en un espacio de funciones» (en rigor serían algoritmos). Para demostrar que el nuevo enfoque es eficaz se ha aplicado a varios problemas matemáticos de la rama de la Matemática Combinatoria, que están en la clase de complejidad NP: para estos problemas obtener una solución es muy costoso (se dice que son ineficientes), pero verificar que una solución es correcta tiene un coste muy bajo (se dice que es eficiente, o también que tiene una complejidad polinómica).

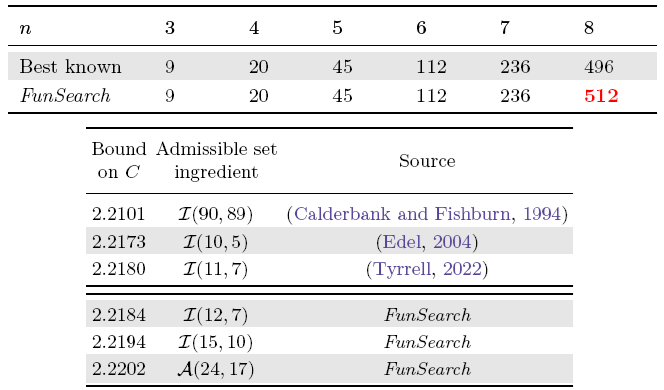
Un primer problema resuelto es el llamado problema del conjunto cap (cap set problem). Inspirado en un juego de cartas que consiste en acumular tres cartas de un conjunto de 81 con 3×3×3×3 propiedades (3 colores, 3 formas, 3 sombreados y 3 números de peticiones) que cumplan que para cada una de sus cuatro propiedades o bien coinciden en las tres cartas, o bien son todas diferentes. Por ejemplo, se gana si las tres cartas tienen el mismo color, pero tres formas diferentes, con el mismo sombreado y en tres números diferentes. Este tipo de conjuntos se llaman conjuntos cap y el problema del conjunto cap consiste en determinar el número de posibles conjuntos cap para n propiedades (en el juego de cartas n = 4). En los programas de ordenador se sustituyen los símbolos por los 0, 1 y 2 ∈ Z₃ de la aritmética entera módulo 3 (la aritmética del reloj pero con solo 3 horas); en dicho caso, un conjunto cap es el que garantiza que n puntos en Z₃n no están alineados formando una recta. Como es obvio, el número de conjuntos cap está entre 2n y 3n; pero en 2016 se demostró que el número máximo está acotado por arriba por 2.756n.
Para algunos valores de n se conoce una cota mínima mayor de 2 (como 2.2173n para n=5 descubierta en 2004 y 2.2180n para n=7 descubierta en 2022). FunSearch ha logrado mejorar estas cotas para n=7 hasta 2.2184n, para n=10 hasta 2.2194n y para n=17 hasta 2.2202n. Además ha permitido obtener un algoritmo que ha logrado el conjunto más grande n=8 con 512 elementos (cuando el récord humano era de 496). No son grandes avances, pues la cota mínima aún está muy lejos de la cota superior. Sin embargo, la ventaja de este método es que FunSearch descubre nuevos algoritmos para resolver este problema, que pueden ser entendidos por los humanos, para descubrir nuevas simetrías en el problema. Esto permitirá a los matemáticos humanos el mejorar estos algoritmos y concebir nuevas cotas aún mejores que las de FunSearch. En los próximos meses no dudo de que se publicarán dichas nuevas cotas. El genio de las matemáticas Terence Tao afirma que el cap set problem es su problema favorito de la matemática combinatoria (porque tiene aplicaciones en el estudio de secuencias de números primos); quizás por ello muchos medios se han hecho eco de los pequeños dados por FunSearch.
También se ha usado FunSearch para resolver un problema de empaquetamiento unidimensional (bin packing), tanto construyendo la solución paso a paso conforme llegan nuevos paquetes, como construyendo la solución a partir de todos los paquetes ya recibidos. En ambos casos se han obtenido pequeñas mejoras en alguno de los algoritmos conocidos para resolver este problema. Se trata de los primeros avances ofrecidos por FunSearch, que quizás nos sorprenda con algo útil en los próximos años. Aunque yo espero que lo más relevante sea que inspire nuevas metodologías matemáticas para atacar ciertos problemas de combinatoria. El artículo es Bernardino Romera-Paredes, Mohammadamin Barekatain, …, Alhussein Fawzi, «Mathematical discoveries from program search with large language models,» Nature (14 Dec 2023), doi: https://doi.org/10.1038/s41586-023-06924-6; también recomiendo leer a Simon Frieder, Julius Berner, …, Thomas Lukasiewicz, «Large Language Models for Mathematicians,» arXiv:2312.04556 [cs.CL] (07 Dec 2023), doi: https://doi.org/10.48550/arXiv.2312.04556.
Acabamos el programa con un debate iniciado por María sobre las posibles aplicaciones de ChatGPT en docencia. Yo opino que una integración efectiva de ChatGPT en la docencia requiere que el profesor enseñe a los estudiantes a usar esta herramienta de forma adecuada (en el contexto de la asignatura). Para ello el profesor debe estudiar la herramienta y desarrollar contenidos apropiados para enseñarla. Hay muchos libros sobre cómo ChatGPT puede ayudar a los profesores y a los estudiantes, que pueden ser usados como fuente de inspiración. Pero en muchas materias el profesor tendrá que desarrollar sus propios materiales, lo que implica un alto costo. A los profesores interesados les recomiendo leer Stan Skrabut, «80 Ways to Use ChatGPT in the Classroom: Using AI to Enhance Teaching and Learning,» Stan Skrabut (2023); A.A. Kabir, «Learn ChatGPT: The Future of Learning,» A.A. Kabir (2023); Juanjo Ramos, «ChatGPT for Education,» Juanjo Ramos (2023); y quizás tutoriales genéricos como Pam Baker, «ChatGPT For Dummies,» John Wiley & Sons (2023), y Mike Loukides, «What Are ChatGPT and Its Friends?» O’Reilly Media, Inc. (2023). Debo confesar que desde mayo de 2023 me he leído más de 20 libros sobre ChatGPT y sigo leyendo más, porque aparecen más.
Lo sentimos, pero no hemos alargado mucho y nos vemos obligados a omitir Señales de los Oyentes.
¡Que disfrutes del podcast!
Gracias. Lo mejor, al final, el chupito de aguardiente: «Hablamos de elementos lingüísticos, que no es necesariamente lo mismo que el lenguaje, porque lo lingüístico ya es la lengua articulada, con palabras, con significados, con sentidos, pero cuando hablamos de lenguaje, es simplemente esa capacidad cognitiva que nos ayuda a comunicar, que no siempre es lo mismo que el huésped. ¿Qué viene primero, pensamiento o lenguaje?. No tenemos que pensar el lenguaje como en una lengua, como en palabras y frases como elementos lingüísticos articulados, sino como en esa capacidad de comunicarnos que puede ser perfectamente el pensamiento simbólico. El lenguaje es la interfaz con la que el niño aprende el mundo, con la que se conecta con el mundo, la capacidad cognitiva para comunicarse. Es lo que nos hace humanos.» (He resumido y ordenado la transcripción. Espero no haber tergiversado su opinión).
La postura de Ribes me parece un intento de salvar algún mueble de la debacle del innatismo. No estoy de acuerdo. La capacidad para aprender un idioma es innata en nuestra especie. También los rasgos psicológicos del síndrome de domesticación. Pero es el aprendizaje de cada idioma lo que nos proporciona esas capacidades cognitivas (https://www.youtube.com/watch?v=2mrjJJwafh4). En el debate sobre filosofía del lenguaje que menciona, apuesto por el otro equipo (Luria y Vygotsky, Sapir y Whorf, Wittgenstein y la escuela de Oxford, Everett y Boroditsky). Socas se equivoca cuando dice que los LLM entienden el lenguaje. Se acerca cuando pregunta si las capacidades cognitivas humanas serán fruto del lenguaje. Y casi da en el clavo cuando dice que le gustaría pensar que «la inteligencia humana es el resultado de algún tipo de desarrollo tecnológico». La inteligencia no, pero el pensamiento sí lo es. Los idiomas son tecnologías comunicativas. Su fonética, su gramática, su semántica y su pragmática, son invenciones. El cerebro humano creció por la presión selectiva de pertenecer a un grupo social que usa esa herramienta para todo. Y no la inventamos como especie, sino en culturas concretas que dieron forma a la especie (efecto Baldwin, coevolución genético-cultural y selección de grupo). Pero no se produjo una asimilación genética del lenguaje. Simon Kirby nos explica (The Language Organism: Evolution, Culture, and What it Means to be Human. https://www.youtube.com/watch?v=f3-R3Ii35nY) por qué un órgano que nos permite aprender y la evolución cultural, en tandem, son mucho más eficaces para la creación y permanencia de usos lingüísticos de lo que podría conseguir un proceso de asimilación genética. Y las palabras son los ladrillos del pensamiento. El cerebro no segrega pensamientos como el páncreas insulina, ni traduce los pensamientos en palabras. Cada pensamiento es un caso lingüístico, ya sea en voz alta o como planificación de conducta verbal (durante la adquisición del lenguaje por el niño, en ese orden, segun Vygotsky). En mi opinión, no hay pensamiento sin idiomas. Lenguaje es el término que usamos para hablar de cada uno o del conjunto de los idiomas.
Respecto a la afasia mental y la afantasia, soy escéptico. «¿Al pensar escuchas una voz dentro de tu cabeza?». La pregunta puede llevar a equívoco. Hay gente muy literal. No escuchamos una voz como si otra persona nos estuviese hablando. Y menos, dentro de la cabeza. Imaginamos una voz (algunos, también la grafía de las palabras). La imaginación es percepción atenuada, en segundo plano. Como dice Villatoro, algunos imaginamos y recordamos imágenes, sonidos, texturas, olores, casi con la intensidad de una alucinación (el extremo de no distinguir entre imaginación y percepción). Para otros, ese segundo plano es tan tenue que nunca le prestan atención (solo somos conscientes de aquello a lo que prestamos atención). Sería una capacidad atencional no desarrollada o atrofiada. Pero no ser consciente de usar palabras para pensar no es lo mismo que no usar palabras para pensar. Lo segundo es imposible. Se me ocurre una forma de comprobarlo. Subvocalizamos muy levemente al pensar, también sin darnos cuenta. Supongo que bastaría con hacer una electromiografía del cuello y la boca a personas con afasia mental y pedirles que piensen.
Sobre conversaciones entre dos IA:
https://www.youtube.com/watch?v=vHcLBzuI6vk
Muy clara y entretenida tu lección de la historia y el estado del arte de la cosmología en la entrevista que te ha hecho Universo de Misterios:
https://www.ivoox.com/874-de-lo-iba-a-ser-audios-mp3_rf_121571159_1.html