


Los modelos epidemiológicos sencillos, como SIR de Kermack–McKendrick (1927), son demasiado sencillos para modelar una epidemia real. Para describir la de COVID-19 en Wuhan (China) ya te presenté el modelo SEIRV con parámetros variables (LCMF, 14 mar 2020). Ahora se publica en Nature el modelo SAPHIRE, una extensión del modelo SEIR con parámetros constantes a trozos para describir el efecto del cordón sanitario (medidas de confinamiento y distanciamiento social) de las autoridades chinas. Se estudia el brote principal entre el 1 de enero y el 8 de marzo de 2020 dividido en cinco periodos (1–9 ene, 10–22 ene, 23 ene–1 feb, 2–16 feb y 17 feb–8 mar), con parámetros constantes estimados en cada uno. El modelo estima que el 87 % (con un mínimo del 53 %) de los casos antes de marzo no fueron contabilizados, por ser asintomáticos o tener síntomas leves.
El número de reproducción R0 que estima el modelo SAPHIRE es 3.54 (intervalo 3.40–3.67 al 95 % C.L.), para el primer periodo. Como ya sabrás el número de reproducción Rt varía con el tiempo; así las sucesivas medidas de confinamiento lograron reducir en Wuhan el número de reproducción a 3.32 (3.19–3.44) en el segundo periodo, 1.18 (1.11–1.25) en el tercero, 0.51 (0.47–0.54) en el cuarto y, finalmente, 0.28 (0.23-0.33) en el último. Recuerda que el valor del número de reproducción depende de la epidemia concreta y del modelo usado para ajustar los datos disponibles; así no se debe extrapolar el valor para Wuhan con el modelo SAPHIRE de este artículo a otras ciudades, provincias, países o continentes. La epidemiología tiene una fuerte componente social, con lo que depende del comportamiento humano y de las decisiones políticas que se toman. Simplificar una epidemia a un modelo SIR y un R0 constante solo es razonable para divulgación a un público lego.
El artículo es Xingjie Hao, Shanshan Cheng, …, Chaolong Wang, «Reconstruction of the full transmission dynamics of COVID-19 in Wuhan,» Nature (16 Jul 2020), doi: https://doi.org/10.1038/s41586-020-2554-8; también cito los estudios serológicos publicados en Xiaodong Wu, Bo Fu, …, Yong Feng, «Serological tests facilitate identification of asymptomatic SARS‐CoV‐2 infection in Wuhan, China,» Journal of Medical Virology (20 Apr 2020), doi: https://doi.org/10.1002/jmv.25904.

El modelo SAPHIRE divide la población de Wuhan en varios grupos: susceptibles de contagiarse (S), expuestos o contagiados que aún no pueden contagiar (E), presintomáticos o contagiados que ya pueden contagiar (P), asintomáticos o contagiados no contabilizados (A), sintomáticos o contagiados contabilizados (I), hospitalizados o aislados por prescripción médica (H), recuperados o fallecidos (R). Como puedes ver en la figura los S que se contagian pasan a E, hasta que su carga viral crece hasta poder contagiar y pasan a P; de aquí pueden pasar a A o a I, según sean sometidos a una RT-PCR que conlleve que sean contabilizados; los I pueden pasar a R o a H. Te incluyo las ecuaciones diferenciales que describen el modelo para que veas que son muy sencillas; en las simulaciones se ha usado un método numérico de Montecarlo no determinista, es decir, se ha simulado la versión estocástica de dichas ecuaciones diferenciales.

Lo más complicado de estos modelos es estimar todos los parámetros a partir de los datos de la epidemia, así como estimar las condiciones iniciales para cada variable (algo que no es fácil cuando hay individuos no contabilizados). Esta tabla te presenta los valores que se han obtenido en este trabajo. Como puedes ver varios parámetros constantes cambian en cada uno de los cinco periodos en los que se ha dividido la epidemia, con objeto de dar cuenta de las diferentes medidas de confinamiento y distanciamiento social adoptadas en Wuhan. Se han estimado estos parámetros y sus incertidumbres mediante un método bayesiano usando el paquete de R llamado BayesianTools; en concreto, se ha usado un método de Montecarlo basado en cadenas de Markov (MCMC) adaptativo de tipo DRAM (Delayed Rejection Adaptive Metropolis), que combina una actualización dinámica (adaptativa) de la matriz de covarianza con un proceso de escalado (rechazo retrasado) de dicha matriz.
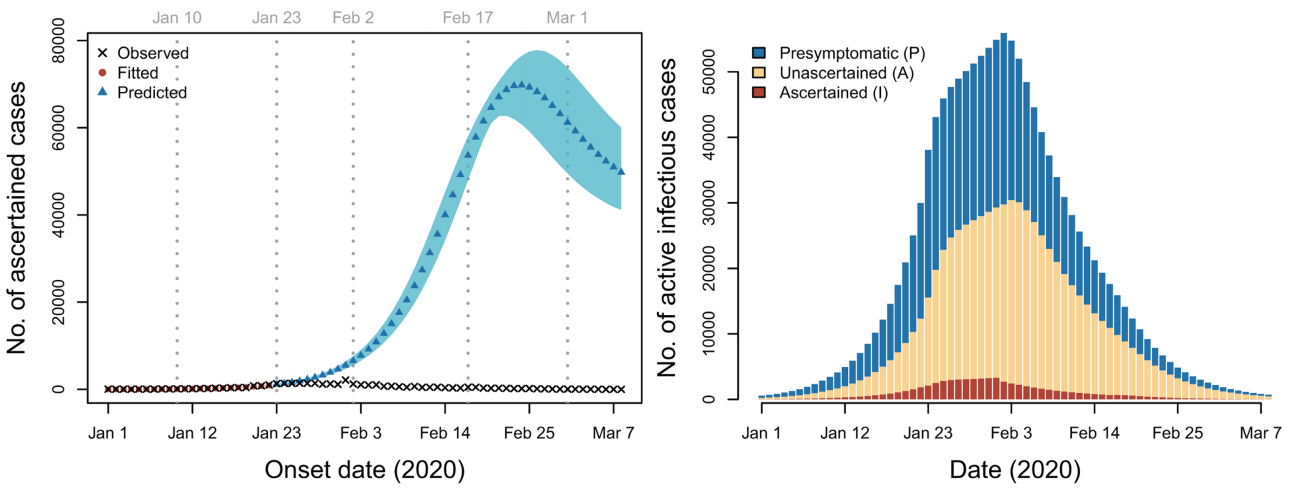
Lo interesante de los modelos es que permiten predecir qué habría pasado si no se hubieran tomado medidas de contención. Esta figura (izquierda) muestra el número de casos estimado si la epidemia hubiera proseguido con sus parámetros del primer periodo (hasta el 22 de enero), el número de contagiados habría ascendido a más de seis millones, en concreto, 6 302 694 (6 275 508–6 327 520 al 95 % C.L.); recuerda que el número de casos estimado por el modelo SAPHIRE es de 249 187 (198 412–307 062), con lo que las medidas de confinamiento han evitado más de seis millones de contagios (y cientos de miles de fallecimientos).
El modelo permite predecir (figura derecha) el número de contagiados no contabilizados (asintomáticos o presintomáticos sin confirmación mediante una prueba RT-PCR). Por supuesto, estos números deben ser considerados como una estimación razonable, pues dependen mucho del modelo. Los estudios de seroprevalencia en Wuhan apuntan a que ~10 % presentan anticuerpos IgG al SARS‐CoV‐2 (eso sí, no son estudios aleatorizados rigurosos como los desarrollados en España, con lo que hay que tomar con precaución este número); en cualquier caso, dicho porcentaje indica que el modelo SAPHIRE subestima a los contagiados no contabilizados.
En resumen, ya sabes que los amantes de las matemáticas disfrutamos viendo fórmulas matemáticas en revistas como Science y Nature (donde casi siempre se suelen relegar a la información suplementaria que casi nadie lee). Quizás te parezca de poco interés la progresión de la epidemia de COVID-19 en Wuhan, dado que se espera que difiera mucho de la evolución en tu ciudad, provincia o país. Aún así, me parece interesante divulgar las limitaciones y los éxitos de los modelos epidemiológicos; en tiempo real es muy difícil confiar en sus pronósticos (salvo quizás a muy corto plazo), pero a toro pasado nos permiten entender bastante bien cómo ha progresado una epidemia. En ciencias sociales (y la epidemiología es una de ellas) predecir el futuro es imposible, sin embargo, las matemáticas nos ayudan a planificar nuestras acciones y a entender sus posibles consecuencias.
Quisiera felicitar al DR. Francisco R. Villatoro por ésta bitácora. Excelente.